[ML] Coursera Machine Learning Week1. 정리
코세라 머신러닝 강의 1주차를 복습하며 정리한 것입니다. (개인공부용)
Training Set → Learning Algorithm →

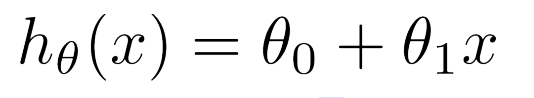
💡 Idea : h(x)가 우리의 트레이닝예제 (x, y)에 가깝게 만드는 최적의 세타원, 세타투를 고르기
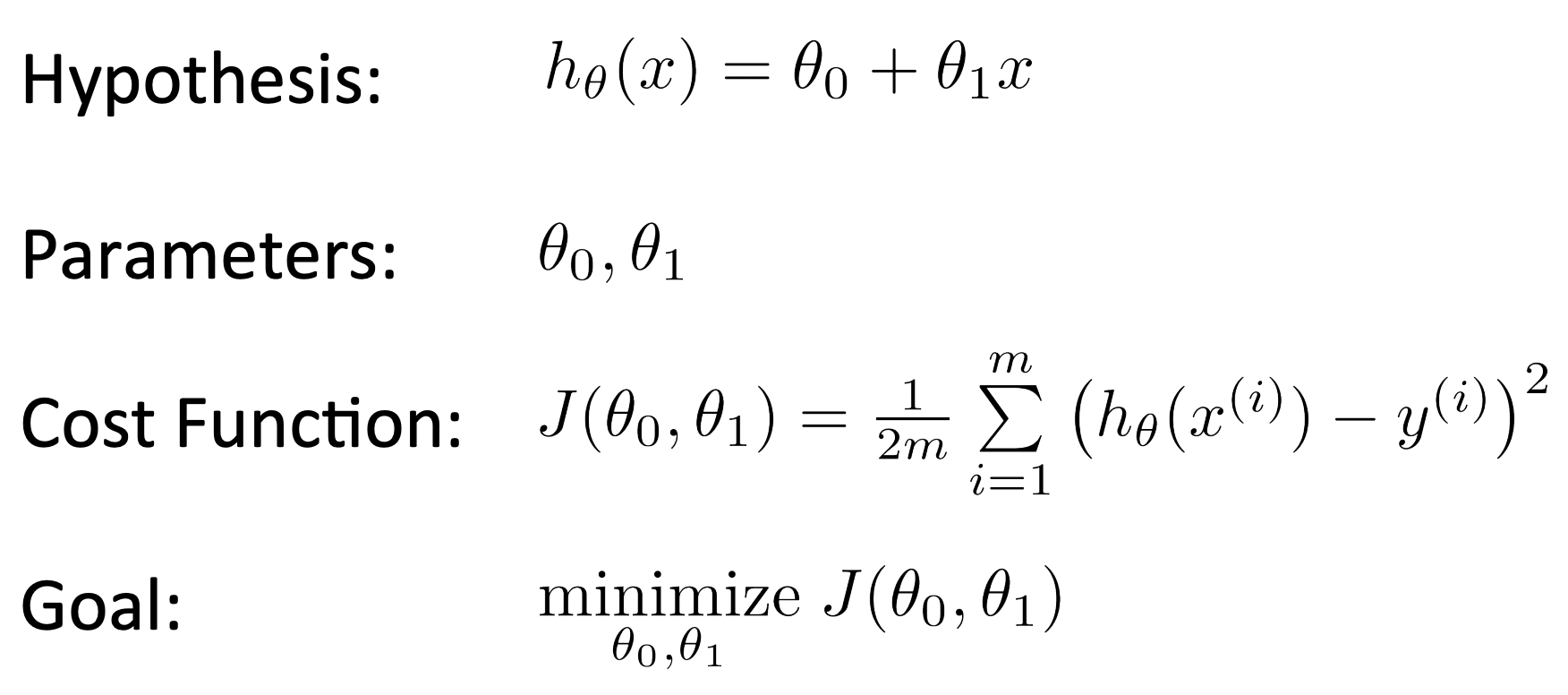
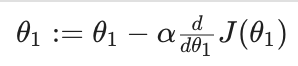

1. Machine Learning Intro.
1-1. Machine learning algorithms
- Supervised learning (지도학습)작업을 수행할 수 있는 방법을 컴퓨터에게 가르치는 것
- Unsupervised learning (비지도학습)컴퓨터가 스스로 학습하도록 유도
- Others: Reinforcement learning, recommender systems.
1-2. Supervised Learning (지도학습)
"Right answer" 정답이 포함된 데이터 → 정답 도출
- Regression연속된 값을 가진 결과를 예측하려 함 (eg. 가격예측)
- Classification불연속적 결과 값 예측 (이산값; 0, 1 또는 세 가지 이상..)
1-3. Unsupervised Learning (비지도학습)
- Clusting Algorithm알아서 구조를 찾아냄(eg. 구글뉴스-수만개의 기사들을 자동으로 묶어줌. 같은 토픽은 묶여서 표시)
- label이 없다 → 이것으로 무엇을 할 지, 각 데이터가 무엇인지 알 수 없다.
2. Linear Regression with One Variable
2-1. Model representation
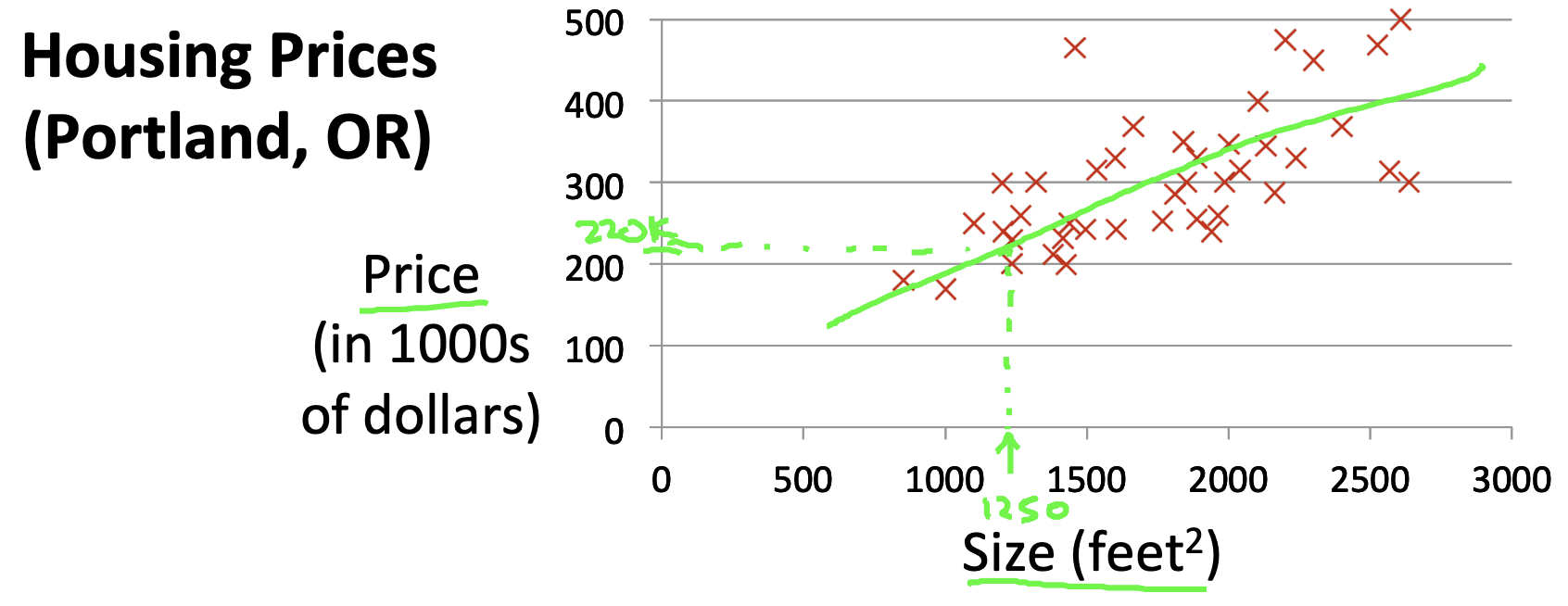
(예시) Housing Prices
- Supervised Learning (지도학습)"Right Answer"을 준다.
- Regression Problem실제값을 예측한다. (가격을 예측하는 회귀)cf) Classification : 이산값 예측
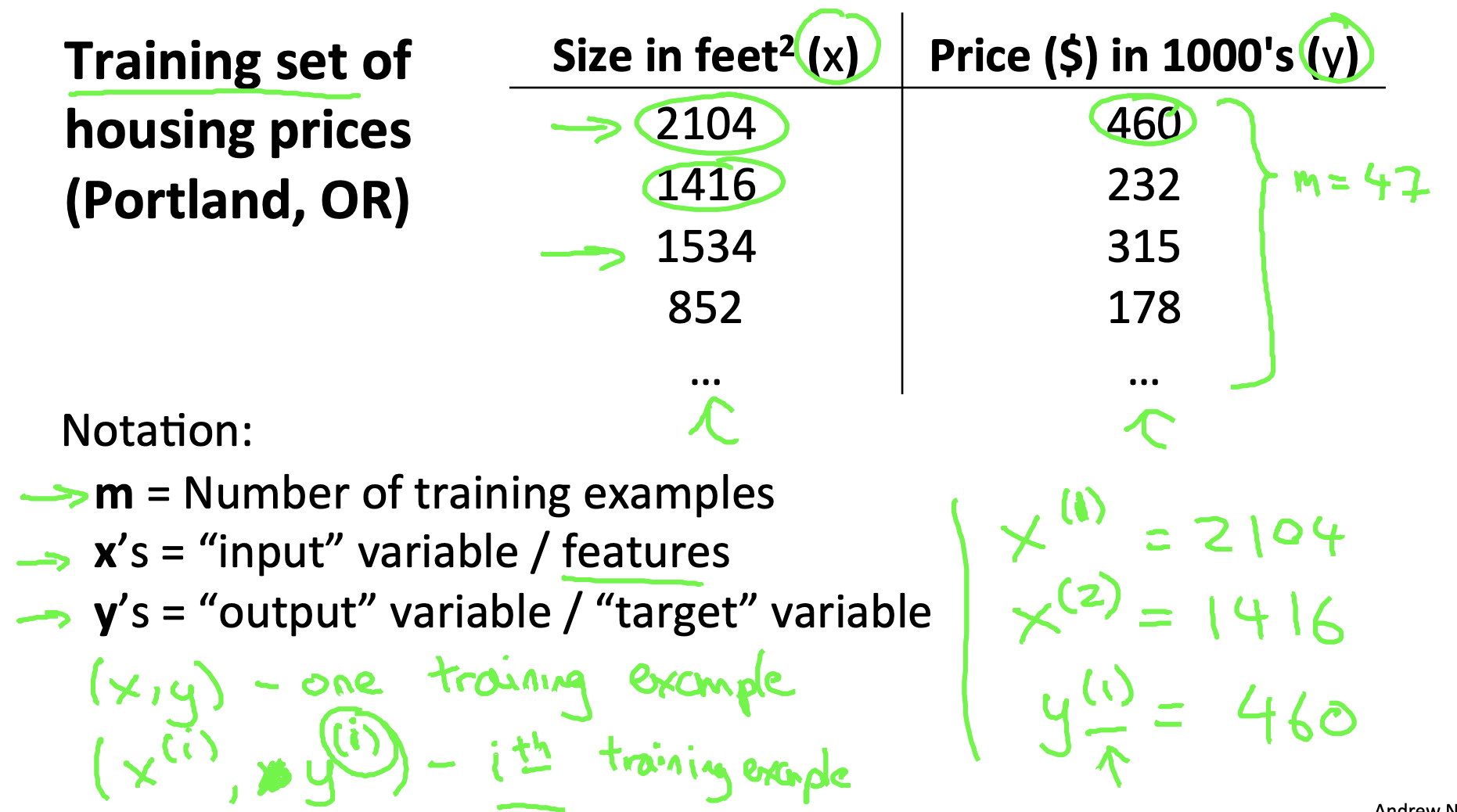
- Training set = Data Set
- m = 학습 예제의 갯수
- (x, y) : 하나의 학습 예제
- (x(i), y(i)) : i번째 학습 예제
h (hypothesis)
x →
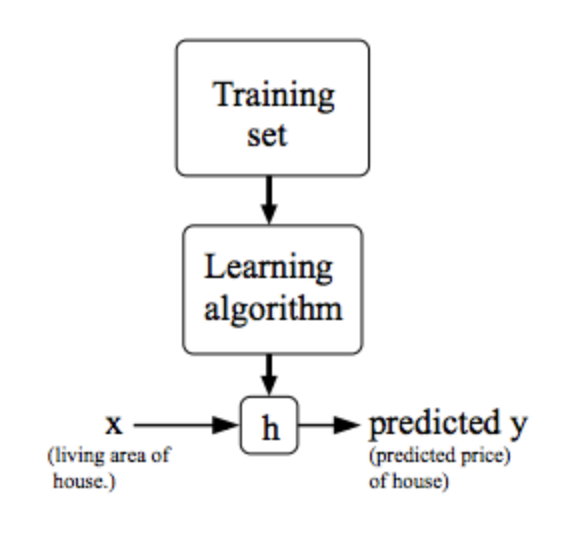
h-> estimate value of yh 는 x에서 y까지의 지도(supervise)이다.
Linear regression (선형회귀)는 1차함수(학습모델)을 유도하는 것
2-2. Cost function
파라미터(세타원, 세타투)를 어떻게 결정할지!!?
[cost function 함수]

1/2m인 이유 : 미분한뒤에 값을 더 깔끔하게 하기 위해, 1/2를 해준다고 해도 결과의 의미에 큰 차이는 없다.
제곱하는 이유 : 음수값 보정, 차이나는 값에 패널티를 주기위해
비용함수 J의 최소값과 비슷할수록 더 좋은 가설이다.
2-3. Gradient descent
- 언덕위 한 점에서 밑으로 내려가는 가장 빠른 길 찾기!
- 시작위치에 따라 도착위치가 다르다..! = 출발위치에 따라 **지역최소값(Local Minimum)**이 다르다.
:= : 할당기호. 프로그래밍에서 = 과 같다.
세타원, 세타투는 동시에 업데이트 되어야한다!
알파 : learning rate로 경사감소비율
- 알파가 너무 작으면, 경사하강의 속도가 느려진다.
- 알파가 너무 크면, 큰 거리이동으로 최소값에서 멀어지고 방향전환이 힘들다.
- 지역최소값으로 접근할 때, 갈수록 조금씩 이동하게 된다. 따라서 알파값을 감소할 필요는 없다. (고정시켜도 ㄱㅊ)
2-4. Gradient descent for linear regression
- 세타원, 세타투의 업데이트는 동시에!!!
- 선형회귀에서 cost function은 항상 활 모양(볼록함수) → 어느 점에서 시작해도 global minimum으로
"Batch" Gradient descent (집단 기울기 하강)
"Batch" : 세타값이 한 번 업데이트 될 때마다 모든 training examples를 사용한다.
댓글
댓글 쓰기